Build with mem0
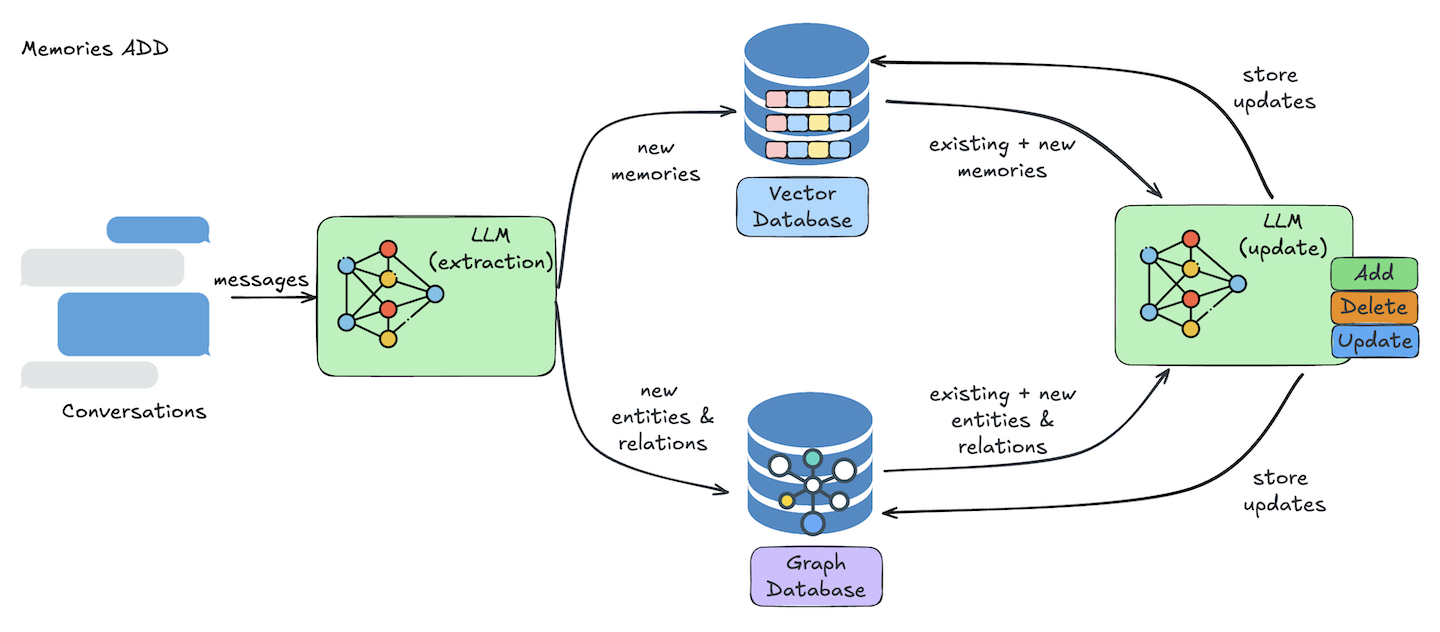
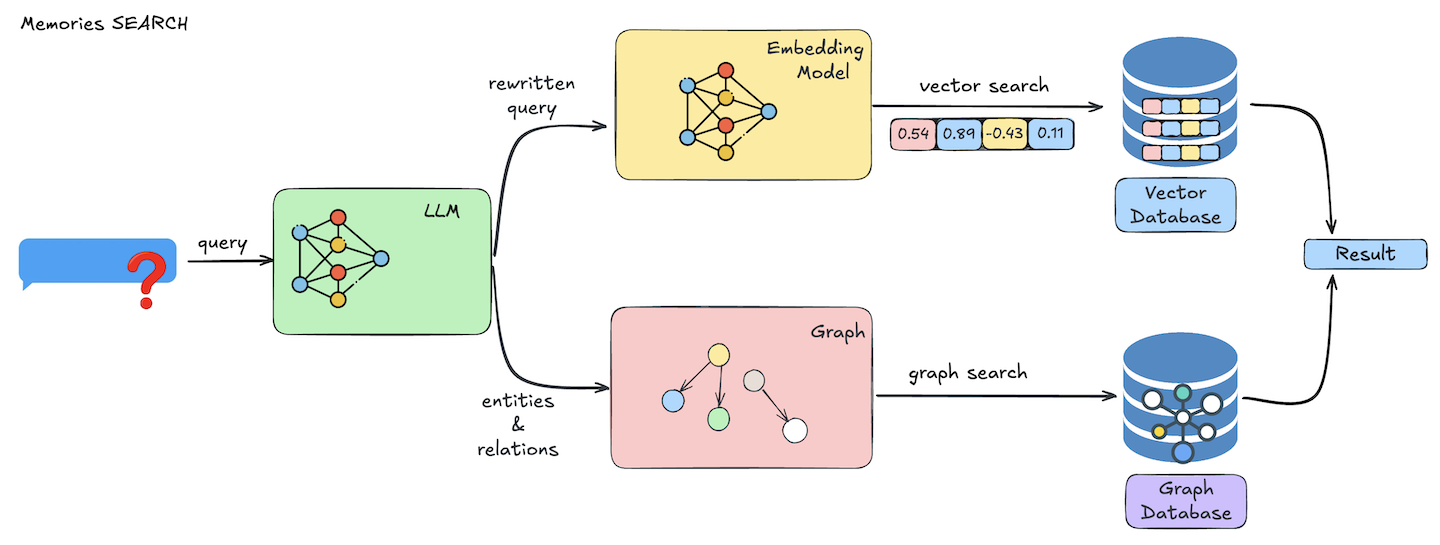
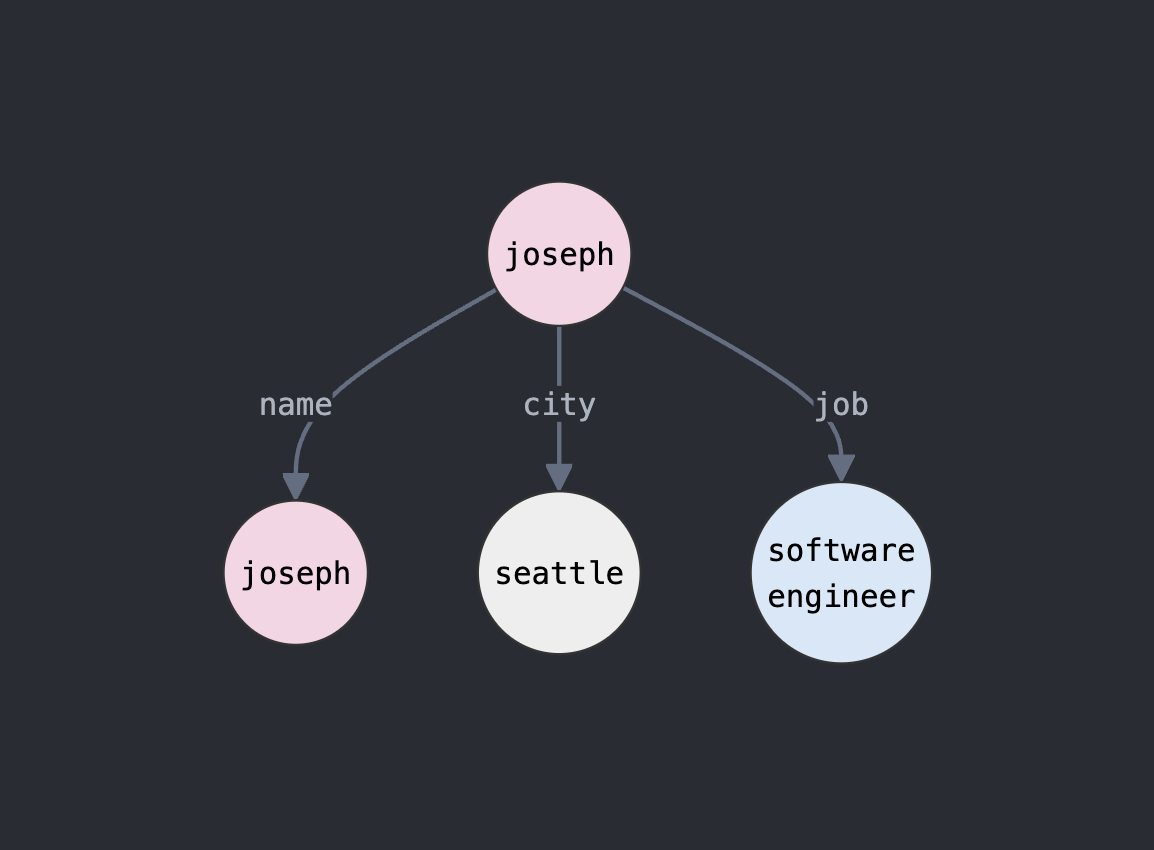
Universal, Self-improving memory layer for LLM applications.
Write your first memory →Mem0 Products



Developer Resources



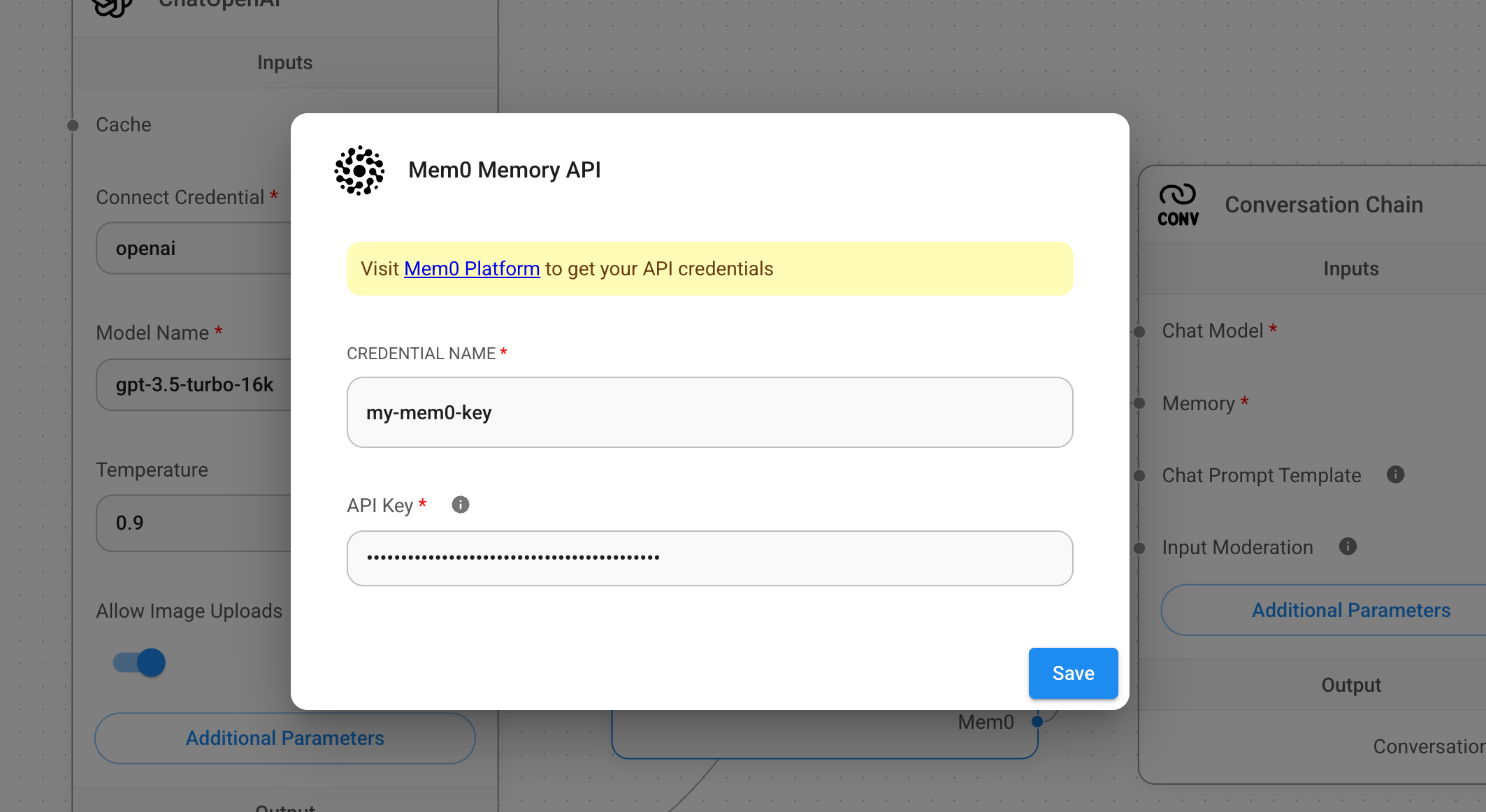
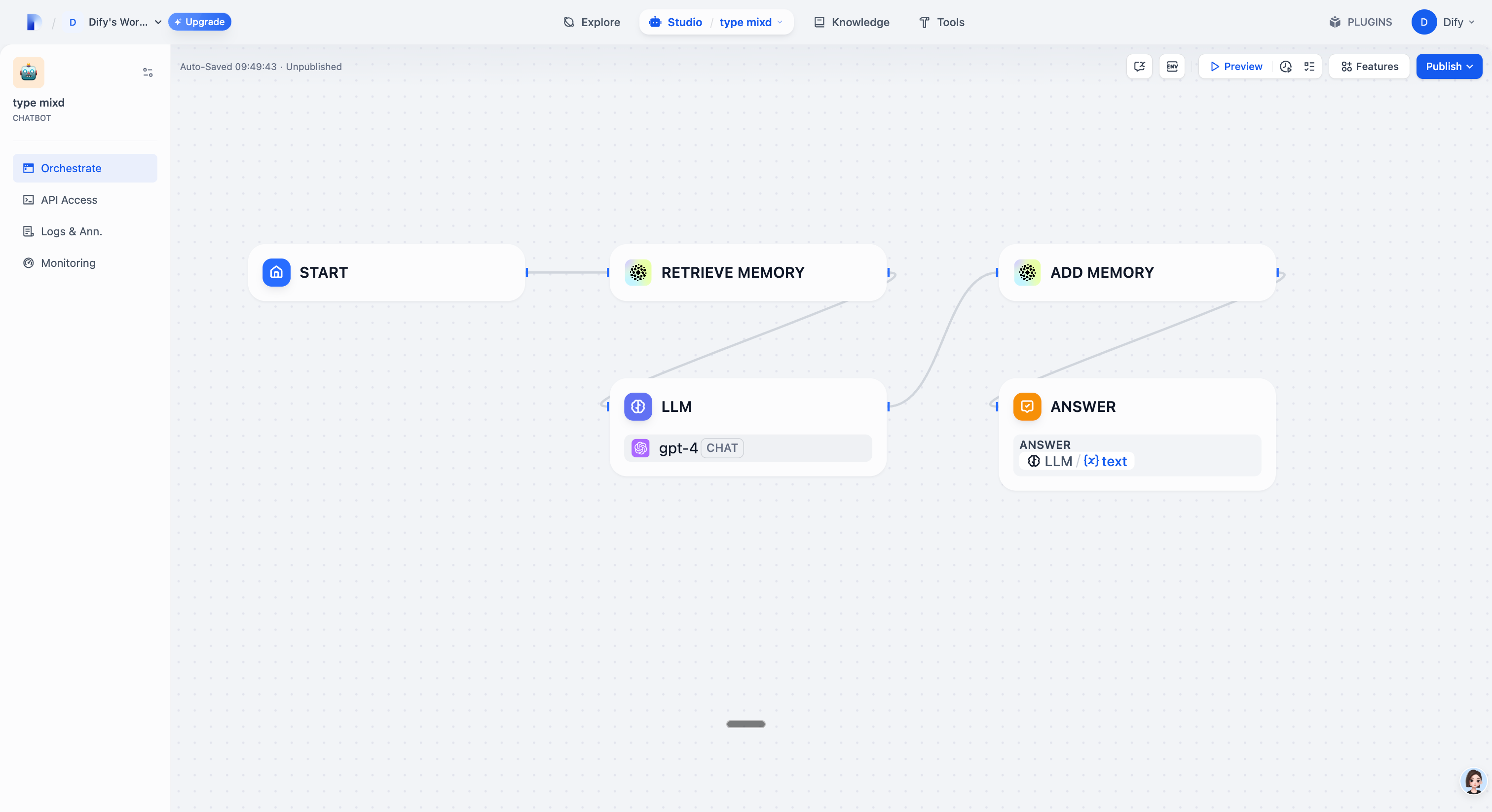 Enhance your Dify-powered AI with Mem0 and transform your conversational experiences. Start integrating intelligent memory management today and give your agents the context they need to excel!
Enhance your Dify-powered AI with Mem0 and transform your conversational experiences. Start integrating intelligent memory management today and give your agents the context they need to excel!